There is a quiet consensus forming among infrastructure engineers who have spent years running serious data and AI workloads on Kubernetes: the platform is extraordinary at what it was designed to do, and deeply inadequate for what the industry now needs it to do.
Kubernetes was born from Google’s Borg and Omega papers. Its DNA is Google’s web serving infrastructure — stateless, horizontally scalable, CPU-centric, short-lived pods exchanging messages over HTTP. A container starts, serves requests, and dies. State lives somewhere else. The scheduler thinks in terms of milliCPUs and MiB. That model conquered the microservices decade and became the default substrate for virtually every cloud-native deployment.
But the workloads reshaping computing today — distributed ML training, GPU inference at scale, multi-terabyte batch transformations, feature engineering pipelines, RAG retrieval systems — do not fit that model. They are stateful by nature, hardware-affine, iterative, and deeply sensitive to locality. Kubernetes abstracts away exactly the things these workloads depend on.
This post examines how the industry is responding: through new orchestration systems like Ray and Modal, through Databricks’ internal innovations now being open-sourced, through the “neocloud” application layer exemplified by Fireworks.AI, and through a set of VM-level primitives — ZeroBoot, Firecracker SnapStart, Seekable OCI, GCP managed Lustre — that are quietly rewriting assumptions about resource readiness. We then ask the hard question: will Kubernetes evolve into something we might call k8s4ai, or will it be flanked by a higher-level orchestration plane it was never meant to inhabit?
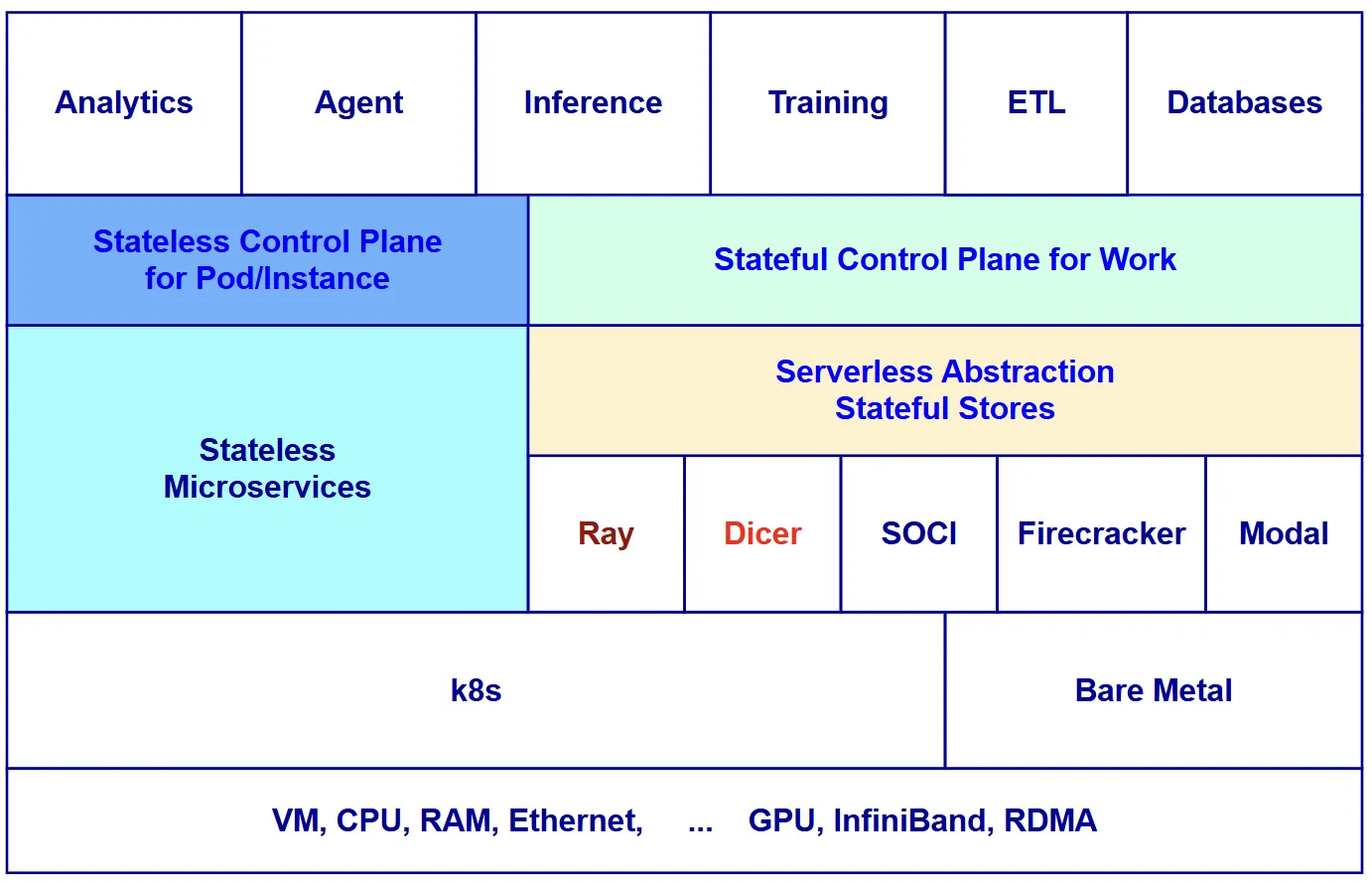
Table of contents
- Part I: What Kubernetes Was Not Built to Understand
- Part II: Ray — Rethinking Compute Abstraction from the ML Workload Up
- Part III: Modal — Serverless Meets the GPU Infrastructure Gap
- Part IV: Databricks Dicer and the Serverless Compute Evolution
- Part V: The Neocloud
- Part VI: The VM-Level Stateful Layer — Below Kubernetes, Above Bare Metal
- Part VII: Will Kubernetes Evolve into “k8s4ai”?
- Part VIII: Databases on Kubernetes — Still Hard, Getting Harder to Ignore
- Conclusion: The Abstraction Stack Is Fracturing — And That Is the Right Outcome
Part I: What Kubernetes Was Not Built to Understand
Before diagnosing what is missing, it helps to be precise about what Kubernetes actually does well. It provides:
- Pod scheduling across a homogeneous node pool, based on resource requests (CPU, RAM)
- Service discovery and load balancing for stateless HTTP/gRPC traffic
- Declarative configuration and reconciliation through controllers and operators
- Horizontal autoscaling keyed to CPU or custom metrics
- Namespace-level isolation and RBAC
For a payment service or an API gateway or a recommendation serving layer backed by Redis, this is a complete and powerful model. The container is the unit of deployment, the node is a fungible compute slot, and state is someone else’s problem.
Data and AI workloads shatter every one of those assumptions:
GPU heterogeneity and locality. An H100 is not a fungible CPU core. CUDA kernels depend on specific GPU architectures. NVLink topology between GPUs within a node matters enormously for collective communication during distributed training. PCIe bandwidth versus NVSwitch bandwidth determines whether a multi-GPU job can saturate its interconnect. Kubernetes can label nodes nvidia.com/gpu: 1 and let the device plugin handle the rest — but it has no model for NVLink topology, GPU MIG partitioning strategy, or NUMA affinity between GPU and local DRAM. The NVIDIA GPU Operator and the Kubernetes Device Plugin framework provide rough hooks, but the scheduler remains fundamentally topology-blind for the cases that matter most.
VRAM and SRAM as first-class resources. A 70B parameter model in fp16 requires ~140 GB of VRAM just to load. KV-cache for inference can consume as much VRAM as the model weights themselves. Kubernetes has no concept of VRAM as a schedulable resource beyond a coarse device count. It cannot reason about whether an already-warm VRAM cache on a node can be reused across consecutive inference requests, whether a partially loaded model checkpoint can be shared, or whether prefix caching from a previous request is still resident. These are exactly the locality questions that determine whether GPU inference is profitable.
Iteration and statefulness within a job. A PyTorch training run is not a request-response pattern. It is a long-lived, stateful computation that checkpoints periodically, communicates gradients between ranks via NCCL collectives over InfiniBand, and must recover from node failures without restarting from epoch zero. Kubernetes Jobs offer no semantics for this. Gang scheduling (ensuring all pods in a distributed training job start simultaneously) required building entirely separate projects — Volcano, Yunikorn, and the Kubernetes-native Kueue — because core Kubernetes scheduling is per-pod and oblivious to job-level atomicity requirements.
High-speed interconnect awareness. InfiniBand and RoCE (RDMA over Converged Ethernet) are the nervous systems of GPU clusters. NCCL all-reduce over InfiniBand at 800 Gb/s is categorically different from Ethernet. Kubernetes networking abstractions — CNI plugins, kube-proxy, Services — are built entirely around TCP/IP and HTTP semantics. RDMA requires kernel bypass, specific hardware (HCAs, smart NICs), and NUMA-aware placement that the Kubernetes scheduler cannot express. The standard workaround is hostNetwork: true, which throws away most of Kubernetes’ networking model.
Large, shared, warm state. A Spark executor that processes 2 TB of data has a shuffle intermediate that must survive task failures and be accessible to downstream tasks — potentially on different nodes. A feature store lookup serving ML training needs a consistent, low-latency view of entity features across distributed workers. A model serving fleet sharing a prefix cache across replicas needs content-aware routing so that a request with a known system prompt lands on a replica that has already computed and cached its KV tensors. Kubernetes Services perform round-robin or IPVS-based load balancing with no awareness of application state. Content-aware routing is not a concept in the control plane.
The cumulative result: running serious AI and data infrastructure on Kubernetes requires a tower of workarounds. NVIDIA GPU Operator, Kueue, Volcano, custom schedulers, node-level DaemonSets for InfiniBand configuration, Multus CNI for secondary network interfaces, CSI drivers duct-taped to fast local NVMe. Each layer patches one gap while introducing new failure modes. The operational surface area is enormous, and the blast radius of a misconfigured RDMA interface or a corrupted NVLink topology mapping can be invisible to the Kubernetes control plane until a training run hangs at 2 AM.
Part II: Ray — Rethinking Compute Abstraction from the ML Workload Up
Ray was not designed as a Kubernetes replacement. It was designed to answer a question Kubernetes never asked: how do you express distributed computation across heterogeneous resources when the unit of work is a Python function, not a container, and when the scheduling decisions must account for data locality, hardware affinity, and task dependency graphs in real time?
Ray’s architecture begins with a fundamentally different mental model. The primitive is the remote task or actor, not the pod. A task is a stateless function that Ray can schedule on any available worker. An actor is a stateful, long-lived object whose methods execute serially on a single worker — the right primitive for a parameter server, a replay buffer in RL, or a streaming aggregation operator.
Ray’s distributed object store (Plasma) is the heart of the model. When a task produces a large output — say, a 10 GB tensor — that result is stored in shared memory on the node where it was computed and referenced by an ObjectRef. Downstream tasks that need that result can access it via zero-copy reads if they run on the same node, or via efficient inter-node transfer if they do not. The scheduler has awareness of object locality and will prefer to schedule dependent tasks where their inputs already reside. This is the cache-locality-sensitive scheduling that Kubernetes fundamentally cannot do.
Ray’s resource model extends naturally to GPUs, TPUs, and custom accelerators. Resources are declared as floating-point quantities, so you can request 0.5 of a GPU for inference tasks that do not need a full device, and Ray will pack multiple such tasks onto a single GPU. More importantly, Ray’s placement groups allow specifying topology-aware bundles — requesting that a set of tasks land on nodes with specific inter-node bandwidth characteristics. This is the scaffolding for expressing NVLink affinity or InfiniBand proximity.
AnyScale’s contribution on top of open-source Ray is primarily around production-grade multi-tenant cluster management, autoscaling that is aware of startup latency for different node types (a g5.48xlarge with 8 A10Gs takes substantially longer to initialize than a c6i.xlarge), and failure recovery at the level of distributed training jobs rather than individual pods.
What Ray does not solve is the lower-level infrastructure: it still runs on nodes that must be provisioned, it relies on the underlying networking for inter-node communication, and its actor model introduces distributed garbage collection challenges that can cause subtle performance cliffs. But for the orchestration layer — the control plane that decides what runs where and when — Ray’s abstractions are dramatically better suited to ML workloads than Kubernetes’.
Part III: Modal — Serverless Meets the GPU Infrastructure Gap
Modal’s insight is different from Ray’s. Where Ray builds a better distributed compute runtime, Modal asks: what if the entire infrastructure experience — provisioning, dependency management, scaling, cold start — was rebuilt from scratch with GPU workloads as the primary design constraint?
Modal’s architecture is not publicly documented in full, but its host overhead analysis for inference reveals the engineering priorities. The post quantifies the host overhead — time spent on the CPU side of a GPU inference call attributable to the Python runtime, serialization, framework overhead — and shows how it can dominate total latency for short inference calls. This is a measurement most Kubernetes-based inference platforms never make, because the abstraction layers are too thick to expose it.
Modal’s key innovations cluster around startup latency elimination:
Container image caching and snapshotting. Rather than pulling and decompressing a container image on every cold start — a process that can take minutes for a 20 GB PyTorch image — Modal snapshots the container filesystem after all packages are installed and the model weights are loaded, then restores from that snapshot. The result is that a “cold start” for a GPU function that would take 4-5 minutes on a standard Kubernetes node pool takes seconds. This is conceptually related to AWS Lambda SnapStart (which snapshots JVM-initialized Lambda functions and restores from that snapshot on invocation), but applied to GPU-resident workloads. The pattern across all of these: the industry is converging on snapshot-driven, state-aware resource readiness as the key primitive missing from the vanilla compute stack. Whether it is Firecracker memory snapshots, SOCI lazy loading, ZeroBoot persistent environments, or Stateful MIGs preserving disk state, the common thread is: don’t start from zero every time, carry state forward, be smart about what is already loaded. Kubernetes, operating at the pod scheduling layer, has no model for any of this. These innovations live in the layers below it.
Ephemeral GPU provisioning with locality awareness. Modal can provision a GPU in response to a function invocation, meaning the user never manages a node pool. The infrastructure layer tracks which nodes have warm caches for which model weights and prefers to route subsequent invocations to nodes where the relevant VRAM is already populated. This is the content-aware routing that Kubernetes Services cannot provide.
Fine-grained resource scheduling. Modal supports fractional GPU allocation and can pack multiple concurrent inference requests onto a single GPU using CUDA MPS (Multi-Process Service) or time-slicing, with awareness of the memory implications. This is operationally complex to configure correctly on Kubernetes and almost always done as a coarse per-pod limit.
The broader architectural point Modal demonstrates is that the operational model for GPU workloads needs to invert the Kubernetes assumption. Kubernetes assumes pods are ephemeral and stateless; state is bolted on via PersistentVolumes and StatefulSets. Modal’s model treats the warm GPU state — loaded model weights, populated KV cache, active CUDA contexts — as the primary resource to be managed and preserved. Infrastructure is ephemeral; state is the asset.
Part IV: Databricks Dicer and the Serverless Compute Evolution
Databricks has been running massive stateful compute — Spark jobs, ML training, SQL queries against multi-petabyte lakehouses — at scale for years. Their internal infrastructure innovations are increasingly being open-sourced or documented, and two are particularly instructive.
Dicer is Databricks’ auto-sharding system for distributed query execution, recently open-sourced. The core problem Dicer solves is partition skew: when a Spark or Photon query joins two large tables, the quality of the partition assignment determines whether all executors finish in roughly the same time (good) or whether a handful of partitions containing hot keys cause some tasks to run 10x longer than others while the rest of the cluster sits idle (bad, and extremely common in practice). Dicer dynamically adjusts shard boundaries based on observed data distribution statistics rather than static configuration. It is a stateful, feedback-driven scheduler that Kubernetes has no primitive for — the work assignment decisions depend on runtime data statistics, not just resource availability.
VM boot latency is a second frontier. Databricks’ serverless compute blog post describes achieving a 7x speedup in VM boot time for their serverless compute offering. The techniques involve pre-warming VMs in a ready-but-idle state, snapshotting initialized guest memory after the JVM and runtime libraries are loaded (analogous to AWS Firecracker’s memory snapshot restore), and using customized hypervisor configurations that minimize the startup path. The result is that a Databricks serverless notebook or job can acquire compute resources in seconds rather than minutes, which changes the economics of interactive and short-lived workloads dramatically.
This connects to a broader point: the time between a job being submitted and compute being ready is often dominated not by Kubernetes scheduling (which is fast) but by container pull, image decompression, process initialization, and library loading. For a Spark executor with a 2 GB JVM heap and a dozen Spark libraries, this can be 60-90 seconds. For a PyTorch training job loading a 70B model, it can be 5-10 minutes. The platforms that win on user experience are solving this startup latency problem at the hypervisor and snapshot layer, below where Kubernetes operates.
Part V: The Neocloud
The neoclouds — Fireworks.AI, Together.ai, Lepton.ai, Baseten, Cerebras Cloud, SambaNova, Nebius — represent a different response to the Kubernetes gap. Rather than rebuilding the orchestration model (like Ray) or the infrastructure experience (like Modal), they focus on application-layer optimizations on top of specialized hardware, and they accept that Kubernetes is an adequate-but-imperfect substrate for the cluster management layer.
Fireworks.AI’s engineering work focuses on the inference serving layer: batching strategies (continuous batching vs. static batching), speculative decoding, quantization schemes (GPTQ, AWQ, fp8), and KV cache management. These are optimizations that operate entirely within the inference serving process — the application layer — and have nothing to do with Kubernetes. The Kubernetes layer just ensures the inference server is running on a node with the right GPU.
But neoclouds also reveal an important structural insight: the bottleneck for GPU inference is not scheduler latency or networking overhead — it is VRAM utilization and compute utilization of the GPU itself. An H100 that is 40% utilized because requests are not being batched efficiently is wasting $3/hour. The optimizations that matter are inside the model serving runtime, not in the infrastructure layer. Kubernetes is mostly irrelevant to this layer of the problem.
Where neoclouds do push back on infrastructure is in network topology for multi-node inference. Running a 70B or 400B model across multiple nodes requires tensor parallelism, which requires all-reduce communication between GPUs across nodes. This communication is only fast enough to be practical over InfiniBand or high-speed RoCE networks. Neoclouds either build or negotiate access to clusters with these interconnects, and they configure their inference runtimes to take advantage of them. The Kubernetes networking stack is bypassed for this data plane; it is relevant only for the control plane.
Groq and Cerebras go further, using purpose-built silicon (the GroqChip LPU and Cerebras Wafer-Scale Engine) that renders the GPU-VRAM abstraction entirely irrelevant. Their orchestration problems are different again — routing inference requests to specific chips, managing disaggregated chip pools — and none of the existing abstractions, Kubernetes or otherwise, fit cleanly.
Part VI: The VM-Level Stateful Layer — Below Kubernetes, Above Bare Metal
There is a set of innovations happening at the VM and hypervisor layer that is easy to miss because it does not fit neatly into any existing orchestration narrative. These systems are adding state awareness, snapshot-based readiness, and locality optimization at the level of the virtual machine — below Kubernetes, but above bare metal.
AWS Firecracker and SnapStart. Firecracker is Amazon’s microVM hypervisor, designed for Lambda and Fargate. It starts a lightweight VM in ~125ms. AWS Lambda SnapStart extends this by taking a Firecracker snapshot of a Lambda function’s memory after the initialization phase (including JVM startup and any @Init code), then restoring from that snapshot on subsequent cold starts. The result is that a Java Lambda function that previously took 1-2 seconds to cold start now starts in tens of milliseconds. The principle is general: snapshot the initialized state, restore from it, skip re-initialization. Applied to ML workloads, this means snapshotting a Python runtime after PyTorch is imported and a model is partially loaded, then restoring from that snapshot for subsequent invocations.
Seekable OCI (SOCI) and lazy loading. Amazon’s Seekable OCI format, also implemented by Grab and others, allows a container to start executing before its image is fully downloaded. Rather than pulling the entire container image before starting the container, SOCI indexes the image so that only the layers containing the files needed for startup are fetched first. Files needed later are fetched on-demand as the process accesses them. For a 20 GB PyTorch image where the first process steps need only Python, NumPy, and a few hundred MB of libraries, SOCI can reduce effective startup latency by 60-80%. This is infrastructure-layer optimization that makes Kubernetes-scheduled pods start faster without changing the Kubernetes scheduler at all.
ZeroBoot. ZeroBoot takes a similar philosophy further: it aims to eliminate boot time entirely for certain classes of workloads by pre-loading the execution environment into a persistent, shared memory space that new processes can attach to instantly. The design is particularly relevant for short-lived, repeatedly invoked functions where initialization cost dominates execution cost.
GCP managed Lustre. Google Cloud’s managed Lustre file system provides high-throughput, POSIX-compatible shared storage optimized for HPC and ML workloads. Lustre is the storage substrate for the world’s largest supercomputers; it is designed for parallel reads and writes at hundreds of GB/s aggregate bandwidth. The relevance for AI infrastructure is checkpoint reading and writing: a 70B model checkpoint is 130+ GB, and reading it from S3 or even EFS is slow enough to be a meaningful source of training time waste. Managed Lustre changes that checkpoint I/O profile fundamentally. It is also a form of shared state that multiple workers can access simultaneously — something Kubernetes PersistentVolumes (with ReadWriteMany semantics) have always struggled to provide with adequate performance for high-throughput workloads.
GCP Stateful Managed Instance Groups. Google’s Stateful MIGs allow a Managed Instance Group — GCP’s autoscaling VM pool primitive — to preserve instance-specific state (attached persistent disks, IP addresses, instance metadata) across VM restarts and replacements. In a standard MIG, instances are interchangeable; a replaced instance gets a fresh disk. In a Stateful MIG, a specific instance is associated with a specific persistent disk, so its local NVMe or SSD state (partial model weights, cached embeddings, warm JVM heap) can survive a restart. This is GCP acknowledging that compute pools for stateful workloads need a different abstraction than the stateless MIG model — and notably, this is a VM-layer primitive that exists below Kubernetes.
Part VII: Will Kubernetes Evolve into “k8s4ai”?
This is the crux of the question, and the answer requires separating several distinct bets about how the infrastructure ecosystem evolves.
The case for k8s4ai — Kubernetes growing upward: Kubernetes has evolved before. It added Custom Resource Definitions, which enabled the operator pattern and transformed Kubernetes into a generic control plane framework. It added the Device Plugin API, which enabled GPU scheduling. Projects like Kueue (job queuing and fair-sharing for batch workloads), LWS (LeaderWorkerSet, for coordinating multi-pod distributed training groups), and the nascent WG-Serving working group are adding AI-specific primitives to the Kubernetes API surface. One plausible trajectory is that Kubernetes continues accumulating CRDs and admission webhooks until it can express topology-aware GPU scheduling, content-aware service routing, VRAM-based resource accounting, and checkpoint-aware gang scheduling — at the cost of a substantially more complex API surface and operator ecosystem.
The case against: The Kubernetes development process is deliberately conservative. Adding a new resource type to the core API requires multi-year consensus across a diverse community with competing interests. The organizations that most need these capabilities — hyperscalers, AI labs, ML infrastructure startups — are not waiting for Kubernetes to catch up. They are building bespoke control planes. Google uses Borg derivatives internally. OpenAI’s infrastructure is not vanilla Kubernetes. Anthropic runs custom cluster management layers. The trajectory of these organizations is away from Kubernetes core, not toward it.
The more likely outcome: Kubernetes persists as the cluster management substrate — handling node health, basic scheduling, container lifecycle, and the control plane framework — while a higher-level orchestration plane emerges above it. This higher plane is what systems like Ray and Modal already represent. It handles:
- Job-level, not pod-level, scheduling decisions
- Topology-aware placement considering GPU interconnect, NUMA, and InfiniBand
- State lifecycle management: when to checkpoint, when to restore, how to handle partial failures
- Content-aware routing for inference (directing requests to replicas with warm KV caches)
- Resource accounting at the VRAM, SRAM, and NVMe level, not just CPU and RAM
The relevant analogy is the relationship between Linux and a distributed system framework. Linux manages processes, memory, and I/O at the OS level. A framework like Hadoop or Spark sits above it and manages distributed computation, data locality, and fault tolerance at a level Linux has no awareness of. Neither replaces the other; they occupy different layers. A similar layering is likely for AI infrastructure: Kubernetes manages the cluster, a higher-level plane manages the distributed workload. The question is whether that higher plane standardizes around an open project (Ray? A future CNCF project?) or fragments across vendor implementations.
What would k8s4ai actually need? If a k8s4ai were to be specified today, the incompatible new APIs would likely include:
- A
TopologyDomainresource that encodes NVLink graphs, InfiniBand fabric topology, and NUMA configurations as first-class scheduling constraints - A
VRAMPoolresource analogous to PersistentVolumeClaim but for GPU memory, with awareness of which model weights are currently resident - A
CheckpointPolicyresource specifying when and where to snapshot job state, with recovery semantics when a node fails mid-iteration - A
ContentRouterresource for L7 routing aware of model context — routing requests with identical system prompts to the same replica to exploit prefix caching - A
GangSchedulingGroupresource as a core API primitive rather than a CRD afterthought, ensuring all components of a distributed training job start together or not at all - An
AcceleratorClassresource that encodes the full hardware capability profile — FP8 support, BF16 throughput, NVMe-to-GPU P2P bandwidth — not just a device count
Building these into a production-grade, multi-tenant, cloud-agnostic control plane is a decade of engineering work. Which is why the more pragmatic prediction is not k8s4ai as a single project but rather a patchwork: Kueue for job queuing, LWS for distributed training topology, the NVIDIA Network Operator for InfiniBand, custom webhooks for VRAM accounting, and Ray or custom schedulers for the workloads where Kubernetes’ scheduler is genuinely inadequate.
Part VIII: Databases on Kubernetes — Still Hard, Getting Harder to Ignore
There is an uncomfortable truth that the Kubernetes community has largely learned to live with: stateless microservices, the native use case for Kubernetes, are entirely dependent on stateful systems — databases, caches, message queues — that Kubernetes was not designed to host.
Every pod serving HTTP traffic that you celebrate as cloud-native is almost certainly backed by a PostgreSQL or MySQL cluster, a Redis or Valkey instance, and an etcd cluster for service coordination. These stateful systems are often running outside Kubernetes, on VMs, on managed cloud services, or on dedicated bare metal — because running them inside Kubernetes introduces a set of challenges that have never been fully resolved.
Why running databases on Kubernetes remains difficult:
Persistent storage with predictable performance. PostgreSQL performance is acutely sensitive to I/O latency and throughput. PersistentVolumes backed by network-attached storage (EBS, Persistent Disk, Azure Disk) introduce latency that is acceptable for most web applications but creates performance cliffs for write-heavy OLTP workloads. Local NVMe via hostPath volumes or local PersistentVolumes gives the right performance profile but breaks the pod scheduling model: a pod tied to a specific node is no longer freely reschedulable, which defeats much of what Kubernetes provides.
Graceful failover and split-brain prevention. A primary/replica PostgreSQL cluster on Kubernetes must handle node failures without split-brain — two nodes both believing they are primary and accepting writes that will diverge. This requires fencing mechanisms, distributed consensus, and careful sequencing of pod restarts. Projects like Patroni, Zalando’s postgres-operator, and CrunchyData’s PGO solve this for PostgreSQL specifically, but the solutions are complex, failure modes are subtle, and operational expertise requirements are high.
Memory and resource isolation. A database process on a shared Kubernetes node competes with other pods for RAM, CPU, and I/O. A noisy neighbor running a memory-intensive batch job can cause the database’s buffer pool to be evicted, triggering a wave of cache misses and disk reads that looks like a sudden performance regression. cgroups and resource limits help, but they do not eliminate contention for the kernel page cache, which database workloads depend on heavily.
Stateful upgrades and schema migrations. Rolling upgrades of a Kubernetes Deployment trivially replace pods one by one. Rolling upgrades of a PostgreSQL cluster require coordinating primary/replica topology, ensuring read replicas are not serving stale schema, and potentially handling replication slot lag. This is stateful coordination that the Kubernetes rolling update mechanism has no awareness of.
The current state of the art: The most operationally successful pattern for running databases near Kubernetes workloads today is not running them inside Kubernetes at all, but using managed cloud database services (RDS, Cloud SQL, Azure Database) connected via VPC peering or Private Link. This gives production-grade availability, automated failover, and managed backups without fighting Kubernetes’ statelessness assumptions. For Redis/Valkey, ElastiCache and MemoryDB provide similar separation.
For teams that genuinely need to run databases inside Kubernetes — for cost reasons, for latency reasons, or because they need control plane integration — the Kubernetes operator pattern has matured significantly. The PostgreSQL operators (Zalando, CrunchyData, CloudNativePG) handle most operational scenarios correctly. Vitess (TiDB as an alternative) makes MySQL horizontally scalable inside Kubernetes. The Cassandra Operator and MongoDB Operator handle their respective databases’ cluster management patterns. These operators work, but they require deep expertise to operate safely.
Predictions for the next 2-3 years:
Disaggregated storage-compute for databases inside Kubernetes. The architectural pattern of separating database compute (the query processing engine) from database storage (the durable, replicated log and data files) is already proven at scale — Aurora, Neon, PlanetScale all use variants of this architecture. As this pattern becomes the standard for databases designed to run in containerized environments, the Kubernetes integration story improves substantially. The compute pods become closer to stateless (they can be replaced without losing data because storage is separate and durable), and the storage layer becomes a cloud service rather than a Kubernetes responsibility. Neon’s open-source serverless PostgreSQL, which separates WAL service, page server, and compute into independent components, is the clearest early example of a database architecture designed for the Kubernetes era.
RDMA-capable storage for database pods. The convergence of NVMe-oF (NVMe over Fabrics) and RDMA in the storage networking layer will enable shared persistent storage that approaches local NVMe latency. Combined with Kubernetes CSI drivers that can consume NVMe-oF targets, this eliminates the performance penalty of network-attached storage for high-IOPS database workloads. Projects like Lightbits Labs and VAST Data are building toward this model.
Kubernetes StatefulSets evolving toward topological awareness. StatefulSets today provide stable pod identity and ordered startup/shutdown, but no awareness of replication topology, data residency, or failover sequencing. A next-generation StatefulSet primitive — call it ReplicaSet with semantic understanding of primary/replica relationships, or a broader DatabaseCluster abstraction — would allow Kubernetes to manage failover-aware pod scheduling directly. The Database Kubernetes Operator pattern is converging in this direction, but having a standard API surface rather than operator-specific CRDs would significantly lower the operational barrier.
Valkey/Redis Cluster running comfortably on Kubernetes by 2027. Redis Cluster on Kubernetes is already more tractable than PostgreSQL, because Redis replication and cluster resharding are more tolerant of the Kubernetes environment. The Valkey fork (Redis’ community successor after the license change) is being designed with cloud-native deployment as an explicit consideration. Expect robust, production-grade Valkey operators to become standard infrastructure by 2027, running comfortably inside Kubernetes for most use cases except the most latency-sensitive OLTP scenarios.
Conclusion: The Abstraction Stack Is Fracturing — And That Is the Right Outcome
The story of Kubernetes and stateful compute is not primarily a story of a technology failing. It is a story of a technology being applied beyond its design envelope, and the ecosystem beginning to develop the right abstractions at the right layers.
The emerging picture looks something like this:
┌─────────────────────────────────────────────────────────────────────┐
│ AI / Data Orchestration Plane │
│ (Ray, Modal, Databricks, custom control planes at AI labs) │
│ — GPU topology, VRAM locality, checkpoint state, content routing │
├─────────────────────────────────────────────────────────────────────┤
│ Kubernetes (Cluster Management Substrate) │
│ + Kueue / LWS / GPU Operator / Network Operator │
│ — Node health, pod lifecycle, basic scheduling, CRD framework │
├─────────────────────────────────────────────────────────────────────┤
│ VM / Hypervisor Stateful Layer │
│ Firecracker SnapStart, Seekable OCI, ZeroBoot, │
│ Stateful MIGs, Managed Lustre │
│ — Snapshot restore, lazy loading, fast cold start, shared FS │
├─────────────────────────────────────────────────────────────────────┤
│ Hardware Layer │
│ H100/B200/MI300X, NVLink, InfiniBand, RDMA, NVMe, HBM3 │
└─────────────────────────────────────────────────────────────────────┘
Kubernetes will not disappear. It will remain the cluster management layer that the industry standardized on, and the enormous ecosystem investment — operators, Helm charts, observability integrations, security tooling — means organizations will not rip it out. But the orchestration decisions that matter for AI and data workloads — where to place a training job given NVLink topology, whether to restore from a model checkpoint, which inference replica has the relevant KV cache — will increasingly be made above it, by systems that understand the semantics of these workloads in ways Kubernetes was never designed to.
The decade of Kubernetes as the universal compute abstraction is closing. The next decade belongs to the layer above it, and it is going to be genuinely interesting to watch which projects earn the right to define it.
A few references:
- https://www.databricks.com/blog/open-sourcing-dicer-databricks-auto-sharder
- https://www.databricks.com/blog/evolution-data-engineering-how-serverless-compute-transforming-notebooks-lakeflow-jobs#section-4
- https://www.databricks.com/blog/booting-databricks-vms-7x-faster-serverless-compute
- https://github.com/zerobootdev/zeroboot
- https://modal.com/blog/host-overhead-inference-efficiency
- https://aws.amazon.com/blogs/compute/under-the-hood-how-aws-lambda-snapstart-optimizes-function-startup-latency/
- https://engineering.grab.com/docker-lazy-loading
- https://docs.cloud.google.com/compute/docs/instance-groups/how-stateful-migs-work
- https://www.youtube.com/watch?v=vpM2Gq4RvIU