Defining metrics once in a semantic layer, pre-aggregating and pre-joining with incrementally-refreshed materialized views, and surfacing those MVs transparently through query rewrite is the holy trinity of modern BI serving. Almost no engine delivers all three cleanly. Here is where Snowflake, Databricks, StarRocks/Doris, BigQuery, Redshift, and Trino actually stand.
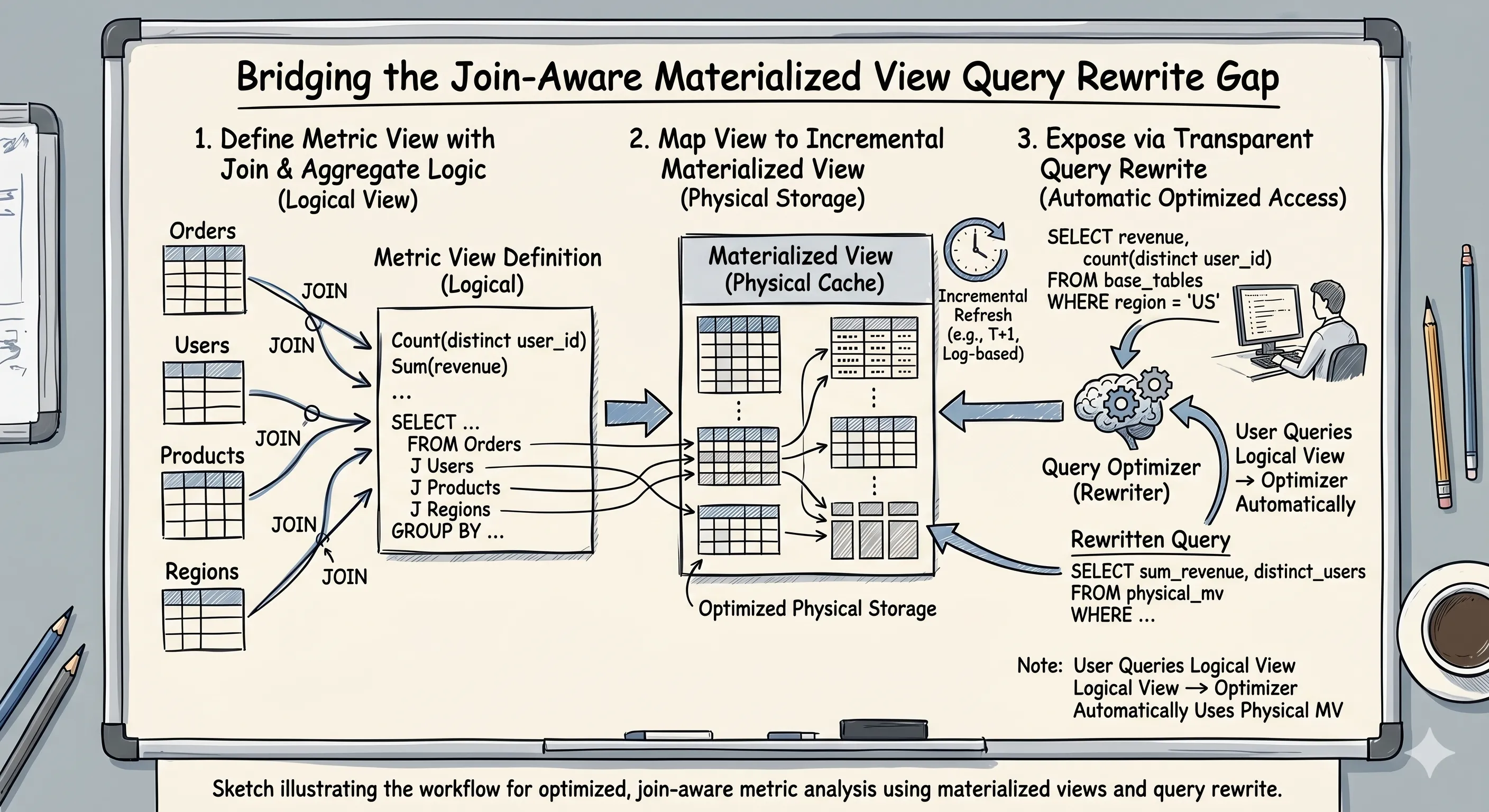
Table of contents
- Why This Matters
- The Three Capabilities, Decomposed
- Engine-by-Engine
- Snowflake — Three objects, no single answer
- Databricks — The integration is the product, but it’s experimental
- StarRocks / Doris — The most complete general-purpose rewrite
- BigQuery — Solid rewrite, but joins break incremental maintenance
- Amazon Redshift — Auto rewrite with an honest freshness gate
- Trino — Federation-first, materialization delegated to the connector
- Summary Matrix
- What the Landscape Actually Tells You
Why This Matters
The dream is simple to state. You define a business metric — net_revenue, active_accounts, gross_margin — exactly once, in a governed semantic layer. The engine pre-computes the expensive joins and aggregations into materialized views, keeps them fresh incrementally as new data lands, and then transparently routes every dashboard query through those MVs without anyone rewriting SQL. Analysts query the logical model; the optimizer silently hits the pre-aggregate.
Three independent capabilities have to line up for that dream to hold:
- A Semantic Layer — define dimensions, measures, and relationships once, decoupled from physical tables.
- Join/Aggregate Materialized Views with Incremental Refresh — pre-compute the expensive work and maintain it cheaply.
- Transparent Query Rewrite — the optimizer substitutes the MV for base-table queries automatically.
-- logic for a monthly materialized view
SELECT
d_d.yyyymm AS calendar_month
d_d.fiscal_quarter, -- or other time grain with rollup hierarchy
d_p.category,
d_r.country,
SUM(f.revenue) AS revenue,
COUNT(f.order_id) AS orders,
MAX_BY(f.order_id, f.revenue, 3) AS top_orders_by_revenue
FROM fact_orders f -- this is the driving table
JOIN dim_product d_p ON f.product_sk = d_p.product_sk
JOIN dim_region d_r ON f.region_sk = d_r.region_sk
JOIN dim_date d_d ON f.date_sk = d_d.date_sk -- this field can trigger the MV refresh
WHERE d_d.fiscal_year = 2025 -- this is just a demo, the actual range can be different
GROUP BY 1, 2, 3, 4
The trap is that vendors market all three as if they compose into one seamless pipeline. They rarely do. The semantic layer is often pure metadata with no materialization behind it. The MV that supports joins often loses incremental refresh the moment a dimension table changes. The query rewrite that works on single-table aggregates often doesn’t fire on the join-containing MV that BI actually needs. The interesting engineering is in the seams, and the seams are where this survey lives.
A note on evidence: vendor documentation tells you how a product wants to be seen, not whether the claim holds in production. Where possible the boundaries below are drawn from behavioral signal — GitHub issues, refresh-limitation tables, and migration write-ups — not marketing copy.
The Three Capabilities, Decomposed
Capability 1 — The semantic layer
Two distinct philosophies have emerged:
- Metadata-only semantic layers define the model but do not themselves materialize anything. Snowflake Semantic Views and (to a large degree) Databricks Metric Views started here.
- Semantic layers wired to materialization let the metric definition drive what gets pre-computed and rewritten. This is the harder, more valuable integration, and it is mostly still emerging.
Capability 2 — Join/aggregate MV with incremental refresh
The universal hard problem. A star-schema MV joins a fact table to several dimensions and groups by attributes from both sides. Incrementally maintaining that under base-table change requires tracking delta propagation across join inputs — and almost every engine narrows the surface drastically the moment joins or non-trivial aggregates enter the picture.
Capability 3 — Transparent query rewrite
The optimizer recognizes that a query against base tables can be answered from an MV and substitutes it — ideally only when the MV is fresh enough to keep results correct. The freshness gate is the part vendors quietly relax to make the feature look better than it is.
Engine-by-Engine
Snowflake — Three objects, no single answer
Snowflake is the clearest illustration of the trinity not composing.
Semantic Views reached GA querying via standard SQL in early 2026. You define facts, dimensions, and metrics, and query with the SEMANTIC_VIEW(...) construct or the AGG() function. They are designed around the star schema and feed Cortex Analyst for natural-language querying. But the critical limitation is architectural: Snowflake’s own documentation describes semantic views as metadata. They define relationships and metrics; they do not materialize, and there is no mechanism by which a semantic view is automatically backed by a materialized view or surfaced through MV query rewrite. The semantic layer and the materialization layer are simply disconnected.
Materialized Views support transparent query rewrite — the optimizer rewrites base-table queries to hit the MV without the user naming it — and they refresh through a serverless background service. But they are restricted to a single base table with no joins, and prohibit HAVING, ORDER BY, LIMIT, window functions, and UDFs. That single-table restriction is precisely what makes them unable to accelerate star-schema BI. (Snowflake docs note the optimizer may substitute an MV for one table within a user’s join — but that is the MV standing in for a single base table, not an MV that itself contains the join.)
Dynamic Tables support arbitrary joins, unions, and window functions, refreshed on a scheduled TARGET_LAG (minimum one minute, charged to a warehouse). But the optimizer does not transparently rewrite queries to use them — a dynamic table is a standalone object you query by name. As one practitioner framed it, MVs live in the read path (a query-acceleration tool) while dynamic tables live in the transformation path (a pipeline primitive). They are not interchangeable, and neither one alone closes the loop.
The deeper reason for the single-table MV restriction is that Snowflake’s MV maintenance was built around micro-partition delta tracking on one base table; extending that to joins is a much harder invalidation problem, and Dynamic Tables sidestepped it by giving up transparent rewrite.
Net: Snowflake has a semantic layer, has join-capable materialization, and has transparent rewrite — but as three separate features that don’t connect. No single path takes a metric definition to a pre-joined MV surfaced by rewrite.
Databricks — The integration is the product, but it’s experimental
Databricks is further along on connecting the layers, which is the genuinely interesting move.
Metric Views in Unity Catalog provide the headless semantic layer: define dimensions, measures, and relationships once in YAML, query with the MEASURE() function, and serve every BI tool, Genie space, and AI agent from one definition. Notably, SUM(MEASURE(...)) nesting is explicitly unsupported — the abstraction is deliberately constrained.
Materialized Views are a first-class Unity Catalog object that supports multi-table joins and aggregations and refreshes incrementally — only newly ingested rows trigger recomputation, subject to prerequisites. But on their own they are a named serving object; querying them is explicit, not transparent rewrite.
The connection is the recent (early-2026, Experimental) “materialization for Metric Views.” Here Lakeflow Spark Declarative Pipelines maintains MVs behind a metric view, and at query time the optimizer uses aggregate-aware query matching to route a query on the metric view to the best underlying MV, falling back to source tables when none fits. The “unaggregated” materialization type is explicitly aimed at pre-joining expensive sources. This is the closest any major cloud warehouse comes to wiring all three capabilities into one governed object.
The caveats are real and worth stating plainly. It is Experimental. It works only inside the Metric View abstraction, not as a general optimizer capability over arbitrary SQL. And it currently runs only in relaxed mode, which skips the staleness check entirely — the optimizer does not verify the MV is current before rewriting, and also skips matching-SQL-settings and determinism checks. Row-level security or column masking on an MV disables rewrite and forces a fallback to source tables. So the design direction is right, but the freshness guarantee is weaker than the mature engines, and it isn’t production-blessed yet.
StarRocks / Doris — The most complete general-purpose rewrite
StarRocks is the engine that has treated transparent, join-aware rewrite as a core optimizer feature rather than a bolt-on, and it shows.
Since v2.5, StarRocks supports automatic transparent query rewrite based on SPJG-type (Select-Project-Join-Group-by) asynchronous materialized views, built on the well-known “Optimizing Queries Using Materialized Views” rewrite framework. The rewrite covers single-table, join, aggregation, union, and nested-MV scenarios. It handles genuinely advanced cases that most engines don’t attempt: View Delta Joins (the MV joins more tables than the query, and the extra joins are provably lossless via foreign-key/unique constraints) and Join Derivability (the MV’s join type differs from the query’s but provably contains the query’s result, e.g. an MV with a left outer join serving an inner-join query).
Crucially, StarRocks gets the freshness gate right by default. The query_rewrite_consistency property defaults to checked: an MV is used for rewrite only when its data is consistent with the base tables, or — if mv_rewrite_staleness_second is set — when its last refresh falls within the tolerated staleness window. You can opt into loose (no consistency check) or force_mv, but the safe behavior is the default. Async MVs refresh on schedule or manually and support partition-level refresh, which keeps maintenance cheap.
The behavioral signal tempers the marketing, though. The rewrite engine has documented rough edges in the field: a 2025 issue reports occasional duplicate data during refresh specifically under LOOSE consistency; other issues show rewrite-compensation failures where a query that should match an MV silently isn’t rewritten (forcing users to query the MV directly), and partial-result bugs against Iceberg external catalogs. The troubleshooting docs themselves enumerate real constraints — joins plus aggregation together, nested aggregation, window functions, and complex outer-join predicates can all fall outside the rewritable set. So the capability is the most complete on paper and largely lives up to it, but “transparent” has asterisks in production, and the common fallback when rewrite misses is to reference the MV by name.
Apache Doris has been building comparable async MV and transparent-rewrite capabilities on the same conceptual model; StarRocks (which forked from Doris) is the more frequently cited reference implementation for this specific feature set.
BigQuery — Solid rewrite, but joins break incremental maintenance
BigQuery’s smart tuning transparently rewrites queries against source tables to use a materialized view whenever possible, even when the query never names the view, and a daily recommender proposes MVs from repetitive workload patterns. Maintenance is serverless and best-effort (it tries to refresh within about five minutes if the last refresh was over thirty minutes ago).
The boundaries are specific and important for star schemas. MVs can contain joins, and BigQuery recommends putting the fact table leftmost. But:
- Incremental refresh on a join MV only works when the leftmost (fact) table is appended. If a table on the right side of the join changes, the view cannot be incrementally updated and BigQuery reverts to the original query. Right-side dimension churn invalidates the cache.
- The newer incremental materialized views that add
LEFT OUTER JOINandUNION ALLare in Preview — and smart tuning is explicitly not supported for MVs that use them. So you get incrementality or transparent rewrite, not both, on those shapes. - A practical operational trap: a join MV with
max_stalenessthat hasn’t refreshed within the 3-day delta-retention window will fail queries outright, because the incremental rewrite can’t fetch the deltas.
So BigQuery composes capabilities 2 and 3 well for the append-only fact case — which is the common one — but the moment dimensions mutate, the elegant incremental story degrades to full recompute or rewrite is withheld.
Amazon Redshift — Auto rewrite with an honest freshness gate
Redshift has supported automatic refresh and automatic query rewrite for MVs since 2020, including AutoMV, where the system creates materialized views from workload patterns and rewrites eligible queries to use them without any developer action. MVs support multi-table joins and aggregations, and incremental refresh is available — extended in 2024 to zero-ETL integrations and data-sharing consumer tables.
Redshift’s freshness behavior is a strength worth highlighting: only up-to-date MVs are considered for automatic rewrite, regardless of refresh strategy, so rewritten queries always return current results. That is the conservative, correct default — stronger than Databricks’ current relaxed mode.
The boundaries are in the fine print of what’s eligible:
- Automatic rewrite only works with a restricted aggregate set — only
SUM,COUNT,MIN,MAX,AVGqualify.MEDIAN, percentiles,LISTAGG,DISTINCTaggregates, and approximate functions disqualify the MV from rewrite. - Incremental refresh is not supported for MVs defined with outer joins (
LEFT/RIGHT/FULL), the set operationsUNION/INTERSECT/EXCEPT, or several aggregate functions — these force a full refresh.
The pattern rhymes with BigQuery: inner-join, simple-aggregate, append-heavy workloads get the full treatment; outer joins and exotic aggregates fall back to full recompute or lose rewrite eligibility.
Trino — Federation-first, materialization delegated to the connector
Trino is the architectural outlier: a distributed query engine, not a storage system. Its materialized views are implemented by the connector, most maturely the Iceberg connector, where each MV is a view definition plus an Iceberg storage table.
REFRESH MATERIALIZED VIEW can do incremental or full refresh depending on the MV’s complexity and the source tables’ Iceberg snapshot history — for incremental, only delta records are processed and appended, and the snapshot-ids of all source tables are recorded in MV metadata for staleness tracking. The GRACE PERIOD and WHEN STALE clauses give some declarative control over serving stale data versus failing.
Where Trino is weakest is exactly capability 3. Its transparent query rewrite is far less developed than the dedicated warehouses; in practice teams reference the MV directly. A production write-up describing Trino under heavy recent-data query load turned to MVs as a manual acceleration tactic rather than relying on automatic rewrite. And a vendor-adjacent critique (from CelerData, the commercial backer of StarRocks — so weight it accordingly) argues Trino MVs lean on manual rewriting and full-table refreshes and lack local-disk acceleration. Discount the competitive framing, but the underlying shape is corroborated by Trino’s own docs: rewrite is connector-dependent and not the seamless, optimizer-driven substitution the warehouses offer. Trino has no semantic-layer object comparable to Semantic Views or Metric Views; that role is filled by external tools.
Federated MVs across heterogeneous sources - if the requirement is “materialize a join across an Iceberg table, a MySql table, and a PostgreSQL table”, can be achived in both Trino and StarRocks. That is an extended problem/scenario than accelerating a governed star schema.
Summary Matrix
| Capability | Snowflake | Databricks | StarRocks / Doris | BigQuery | Redshift | Trino |
|---|---|---|---|---|---|---|
| Semantic layer object | Semantic Views (metadata only) | Metric Views (headless) | None native | None native | None native | None native |
| Semantic layer drives MV/rewrite | No | Yes (experimental) | n/a | No | No | No |
| MV with joins | No (single table) / Dynamic Table has joins | Yes | Yes (incl. view-delta, derivable) | Yes | Yes | Yes (connector) |
| Incremental refresh on join MV | Dynamic Table (scheduled) | Yes | Yes (partition-level) | Only if fact/leftmost appended | Not for outer joins | Connector-dependent (Iceberg) |
| Transparent query rewrite | MV only (single table) | Metric View only (experimental) | Yes (SPJG, general) | Yes (smart tuning) | Yes (incl. AutoMV) | Weak / connector-dependent |
| Freshness-gated rewrite | Always-fresh MV | No (relaxed mode skips) | Yes (checked default) | Best-effort | Yes (fresh-only) | Snapshot/grace-period |
| All three wired together | No | Partially (experimental) | Rewrite yes, no semantic object | No | No | No |
What the Landscape Actually Tells You
No engine ships the full trinity production-ready. The closest to a connected semantic-layer-to-rewrite pipeline is Databricks’ experimental Metric View materialization, but it trades away the staleness guarantee to get there. The closest to production-grade transparent join-aware rewrite is StarRocks, but it has no native semantic-layer object — you bring your own, and you live with the rewrite engine’s field-reported rough edges.
The join is where everything breaks. Snowflake won’t put a join in a rewritable MV at all. BigQuery and Redshift will, but lose incremental maintenance the moment a dimension (right-side / outer-join) table changes. Only StarRocks treats arbitrary SPJG joins as a first-class rewrite target — and even it carves out join-plus-aggregation and outer-join-predicate edge cases.
The freshness gate is the honesty test. Redshift, StarRocks (default), and Snowflake MVs only rewrite when the MV is current — correct by construction. Databricks’ relaxed mode and LOOSE-mode StarRocks explicitly trade correctness for coverage, and StarRocks has a real-world duplicate-data report under LOOSE to prove the trade-off bites. When evaluating any of these, the first question is not “does it rewrite?” but “does it rewrite only when fresh, and what happens when it isn’t?”
Semantic layers are mostly still metadata. Snowflake Semantic Views and the base form of Databricks Metric Views define the model but don’t, by themselves, make anything faster. The performance win still comes from a separate MV layer, and connecting the two is the frontier — not the settled state.
For a practitioner today, the pragmatic read is: if you need governed metrics and transparent acceleration and correctness guarantees, you are assembling it from parts, not buying it whole. Pick the engine whose seam falls in the least painful place for your workload — append-only facts favor BigQuery/Redshift, complex governed star schemas favor StarRocks’ rewrite paired with an external semantic layer, and an all-in Databricks shop can bet on the experimental path maturing. Snowflake, for all its strengths, still asks you to choose between transparent rewrite (single-table MV) and join expressiveness (Dynamic Table) with no bridge between them and a semantic layer that sits to one side of both.
Stateful Thoughts
Stateful Data team will add “driving table” and “high watermark field” as the additional annotations to the Materialized View definition, so that the orchestration backend can effective detect the data changes (in this example, focusing on fact_order as the driving table and ignoring the 3 dimensional tables) and decide when to trigger a refresh with range of dates as the incremetnal filter. The core design patterns are explained in https://medium.com/@eric-sun/data-dependency-driven-orchestration-d1bd8e1d695f
Sources
Snowflake: Working with Materialized Views · Dynamic tables decision guide · Overview of semantic views · Querying semantic views · Semantic views standard-SQL GA note · Dynamic Tables vs MVs (Tacnode) · MV vs Dynamic Tables (select.dev)
Databricks: Materialization for metric views (Azure docs) · Materialization for metric views (AWS docs) · BI Serving Pointers (Databricks blog) · Databricks MV practitioner guide (Flexera) · Semantic Views vs Metric Views (Medium)
StarRocks / Doris: Query rewrite with materialized views · Asynchronous materialized views · CREATE MATERIALIZED VIEW · Troubleshooting async MVs · Multi-table SPJG rewrite tracking issue · Duplicate data under LOOSE (issue #66320) · Rewrite compensation failure (issue #42621)
BigQuery: Use materialized views · Create materialized views · Materialized view recommendations · Auto-refresh failures and staleness (OneUptime)
Redshift: Materialized views overview · Automatic query rewriting · Automated materialized views (AutoMV) · REFRESH MATERIALIZED VIEW limitations
Trino: Iceberg connector — materialized views · CREATE MATERIALIZED VIEW · REFRESH MATERIALIZED VIEW · Incremental refresh for Iceberg MVs (issue #18673) · Trino MVs in production (DZone) · Trino vs StarRocks (CelerData — vendor-adjacent)